
黒石同様切り取った画像を加工して、Tesseractで手順番号を検出します。
黒石の場合は、周囲の白を黒で埋めることで文字の検出ができましたが、白石は周りの円を消す必要があります。単純に検出した円を白で染めればよいように思いましたが、全くうまくできませんでした。
試行錯誤を繰り返し、かなり泥臭い方法ですが 次のような方法にたどり着きました。
- 上から、高さの1/6+2 までの黒を全て白に置き換える。
- 下から、高さの1/6+2 までの黒を全て白に置き換える。
高さの1/6+2:この数字に根拠はありません。純粋に試行錯誤の結果です。 - 左側から、黒ピクセルの連続が3以下ならば、白ピクセルに置き換える。
- 右側から、黒ピクセルの連続が3以下ならば、白ピクセルに置き換える。
- 黒石同様、縦横3倍のMatを準備し 周囲に白のマージンを設ける。
- 白□(手順番号なし)を判定する。
- 白□以外、Bitmapに変換後 Tesseractで手順番号を検出する。
【元の画像】

【検出結果を電子碁盤用に表示した結果】

(9,17) (11,8) および (17,7) が、認識不能となっています。これら3箇所の文字検出前のMatを拡大すると



となっていて、文字がくっついていることが分かります。
【くっつき対策】を加える。
白のマージンを設ける前に、横方向の中央部6ピクセルを調べ、縦方向に連続して2ピクセルが 黒ピクセルの場合、白に置き換えました。この対策を施した後、手順番号を検出すると下図のように、全て検出できました。
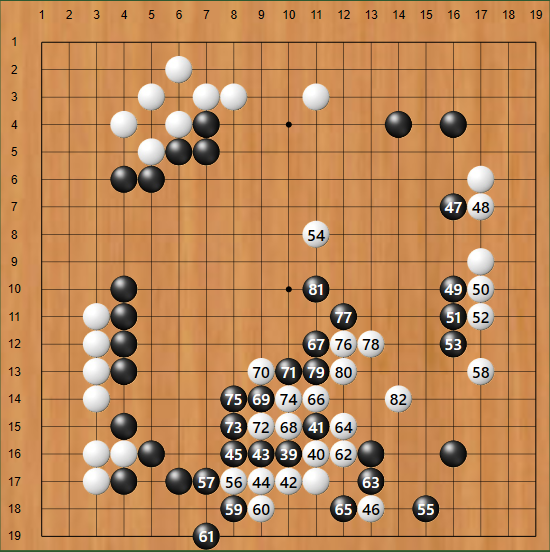
ところで、この文字のくっつき対策、なぜ白石だけで必要なのか不明です。ネガ変換した後処理をすれば 不要だったのかもしれません。
開発環境
OS:Windows10
言語:C#(WPF使用)
IDE:VisualStudio2019
仕様Tool:OpenCvSharp v4.0.0.20181129
Tesseract v3.3.0.0
使用電子本:電子書店パピレスのNHK 囲碁講座 テキスト
OS:Windows10
言語:C#(WPF使用)
IDE:VisualStudio2019
仕様Tool:OpenCvSharp v4.0.0.20181129
Tesseract v3.3.0.0
使用電子本:電子書店パピレスのNHK 囲碁講座 テキスト
0 件のコメント:
コメントを投稿