| 元の画像 | 検出結果 | 誤検出等 | |
| 第 1 図 |  |
 | 誤りなし |
| 第 2 図 |  |
 | 誤りなし |
| 第 3 図 |  |
 | ( 3, 5) 白116を 115と誤検出 (10,7) 白110を 116と誤検出 |
| 第 4 図 | 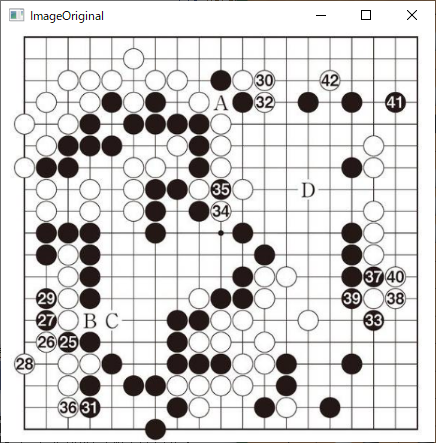 |
 | ( 2,15) 白26 検出不能 |
| 第 5 図 |  |
 | (14,13)白50を 1と誤検出 (17,16)黒47を 41と誤検出 |
誤検出または検出不能となった石の画像を拡大してみると、以下のようになります。
| 元の画像 | 円削除後 (Tesseractの入力) | 誤検出等 | |
| ( 3, 5) 白116 |  |
 | 115と誤検出 |
| (10,7) 白110 |  |
 | 116と誤検出 |
| ( 2,15) 白26 |  |
 | 検出不能 |
| (14,13)白50 |  |
 | 1と誤検出 |
| (17,16)黒47 |  |
 | 41と誤検出 |
この結果では、白石の上2つは、円と文字がくっついていて、うまく円が消去できなかったためと思います。また26と50は、2文字が微妙に離れてはいるものの あまりに近すぎて正しく検出できなかったものと思います。特に最後の白50は、一度検出不能になり、次いで無理やり(??)一文字モードで検出を試みた結果1になってしまいました。
また黒石は、周囲の白を黒で埋める際、7の上の線が消えてしまい1と誤ってしまいました。
電子本から画像を切り取る際、ブラウザ(MEDUSA)の 拡大ボタンで拡大した画像を切り取って、直接使っているのですが プログラム上で拡大処理を加える とか 2値化処理の閾値を調整するなど改良の余地がありそうです。
開発環境
OS:Windows10
言語:C#(WPF使用)
IDE:VisualStudio2019
仕様Tool:OpenCvSharp v4.0.0.20181129
Tesseract v3.3.0.0
使用電子本:電子書店パピレスのNHK 囲碁講座 テキスト
OS:Windows10
言語:C#(WPF使用)
IDE:VisualStudio2019
仕様Tool:OpenCvSharp v4.0.0.20181129
Tesseract v3.3.0.0
使用電子本:電子書店パピレスのNHK 囲碁講座 テキスト
0 件のコメント:
コメントを投稿